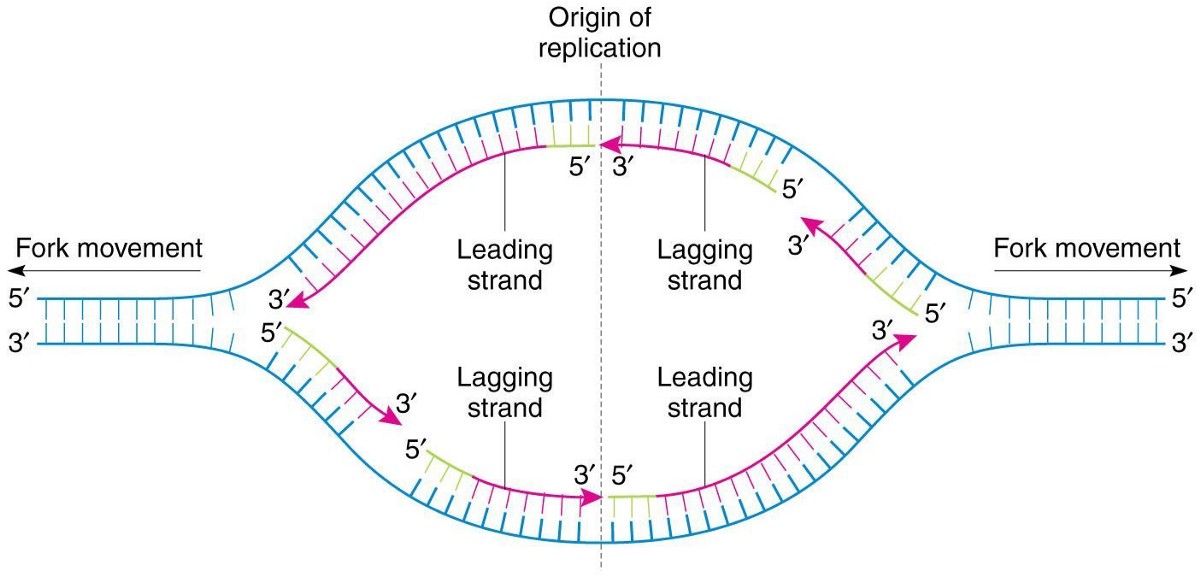
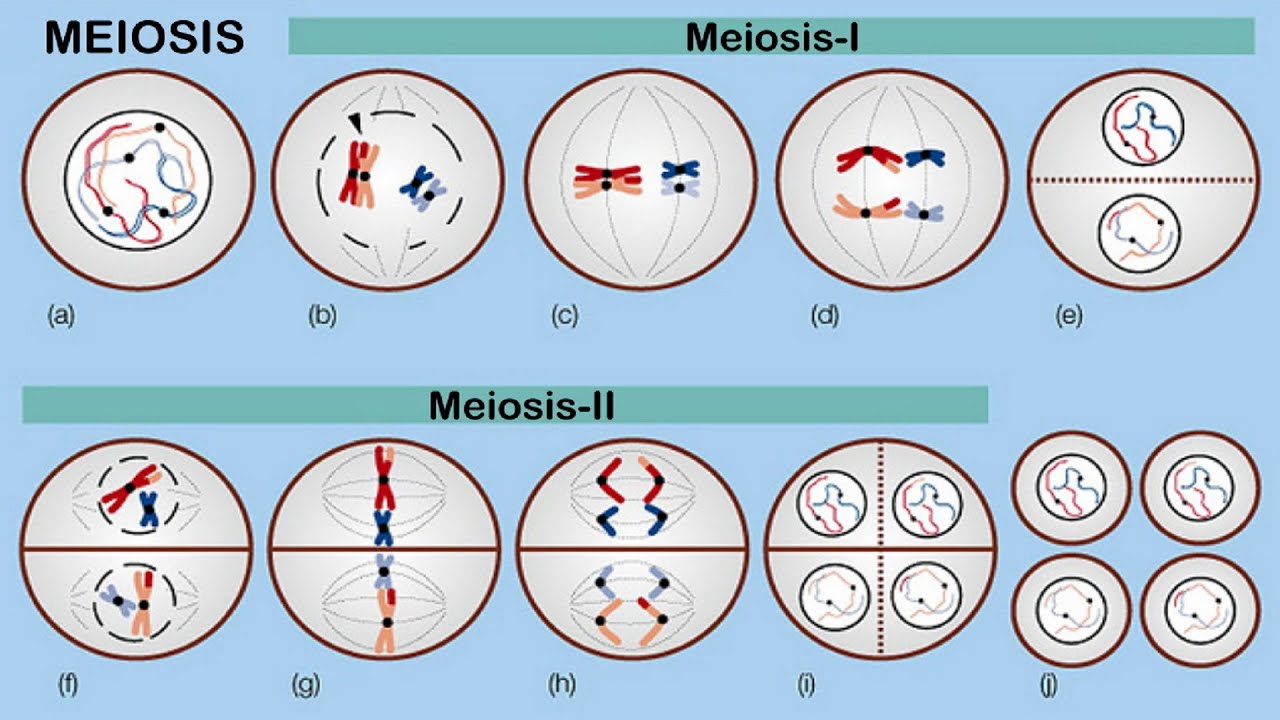
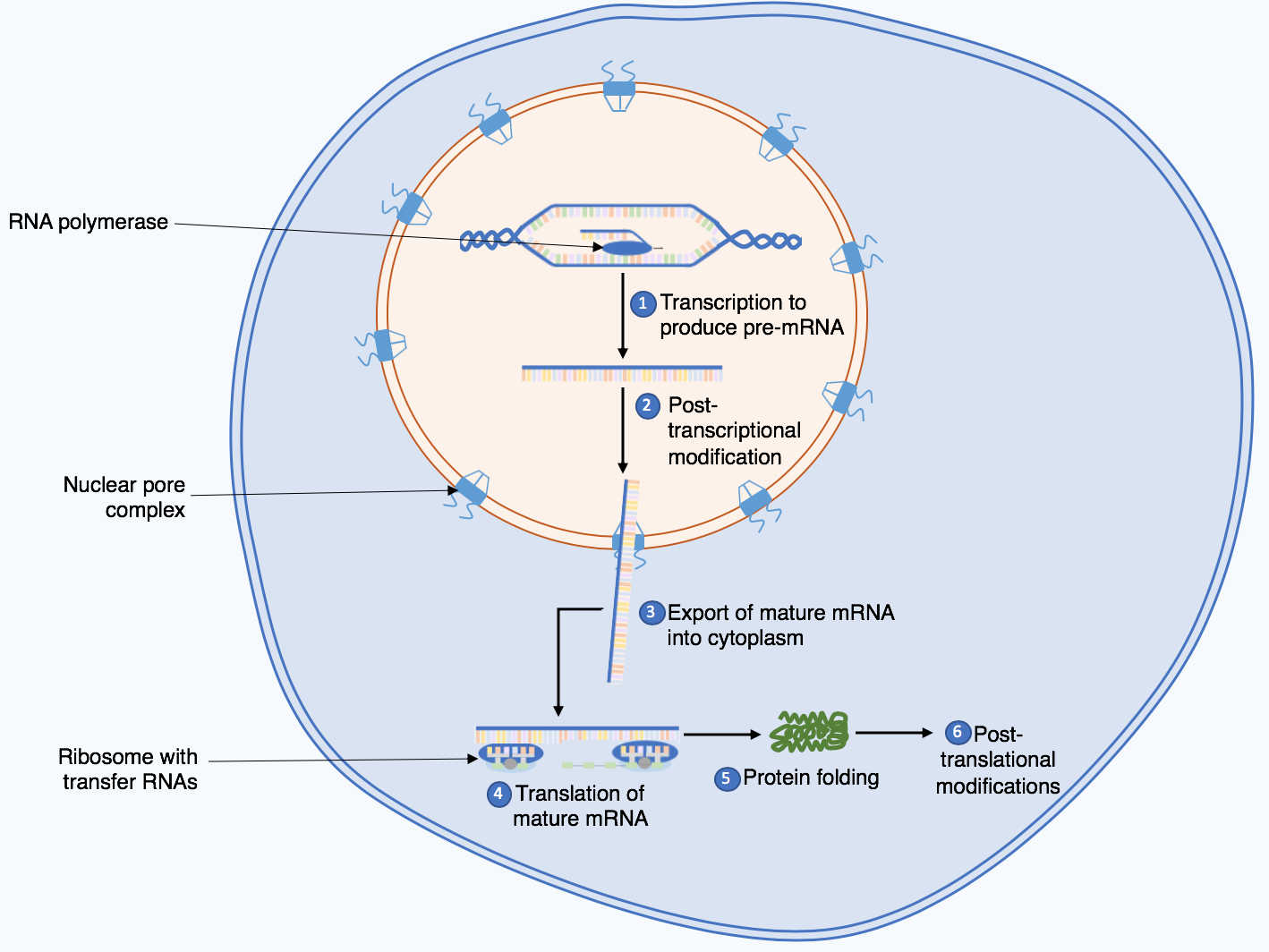
Abstract Eukaryotic cells must accurately and efficiently duplicate their genomes during each round of the cell cycle. Multiple linear chromosomes, a large number of regulatory elements, and chromosomal packaging are challenges that the eukaryotic DNA replication fork machinery must successfully overcome. The replication machinery, the “replisome” complex, is composed of many specialized proteins with functions…